
本ページでは、信用リスクの計測方法の基本的な考え方についてまとめたい。
「そもそも信用リスクとは何か」については、以下のページを参照されたい。
信用リスクの定量化
銀行は、たくさんの企業に貸出(信用供与)することで収益を得ているが、同時に貸し倒れに伴う損失のリスクを負う。
この損失額は、以下のような「確率分布」に従うと考えることができる。

信用リスクによる損失に関する確率分布(損失分布)の特徴として、損失額を大きくしても確率がゼロにならない、すなわち右側に長い裾を持つ形状であることが多いと言われている。これはつまり、莫大な損失の発生を否定できないことを意味する。
この損失分布の特定が、信用リスク定量化の出発点となる。
損失分布の推定
信用リスクの定量化を行うには、損失分布の推定が必要であるが、これはどのように行えばよいのか。推定には以下のステップを踏む必要がある。
①デフォルト確率の推計
各融資先について、その信用度を財務情報や定性情報を用いて格付け・スコアリングする(例えばA,B,Cなど)。そしてそれぞれの区分について、過去のデータ等からデフォルト確率を推計する。これで、各融資先企業について、デフォルト確率が設定されたことになる。
②企業価値とデフォルト閾値の算出
融資先企業がデフォルトするとき、企業価値がある一定の水準(デフォルト閾値)を下回ったものと仮定する。次に行うべきことは、この企業価値と、デフォルト閾値をそれぞれ算出することである。
では、企業iの企業価値はどのように表せるか。マートンの「企業価値モデル」によると、以下の数式で表すことができる。

ここで、Xは各企業に共通な要因を表しており、景気等のマクロ経済状況がこれにあたる。Yは各企業固有の状況を表す固有要因である。(上記の数式は、XとYiがそれぞれ一つずつのシンプルな場合。)aは感応度係数である。X、Yiは互いに独立な標準正規分布に従うと仮定すると、 Zi も標準正規分布に従うことになる。
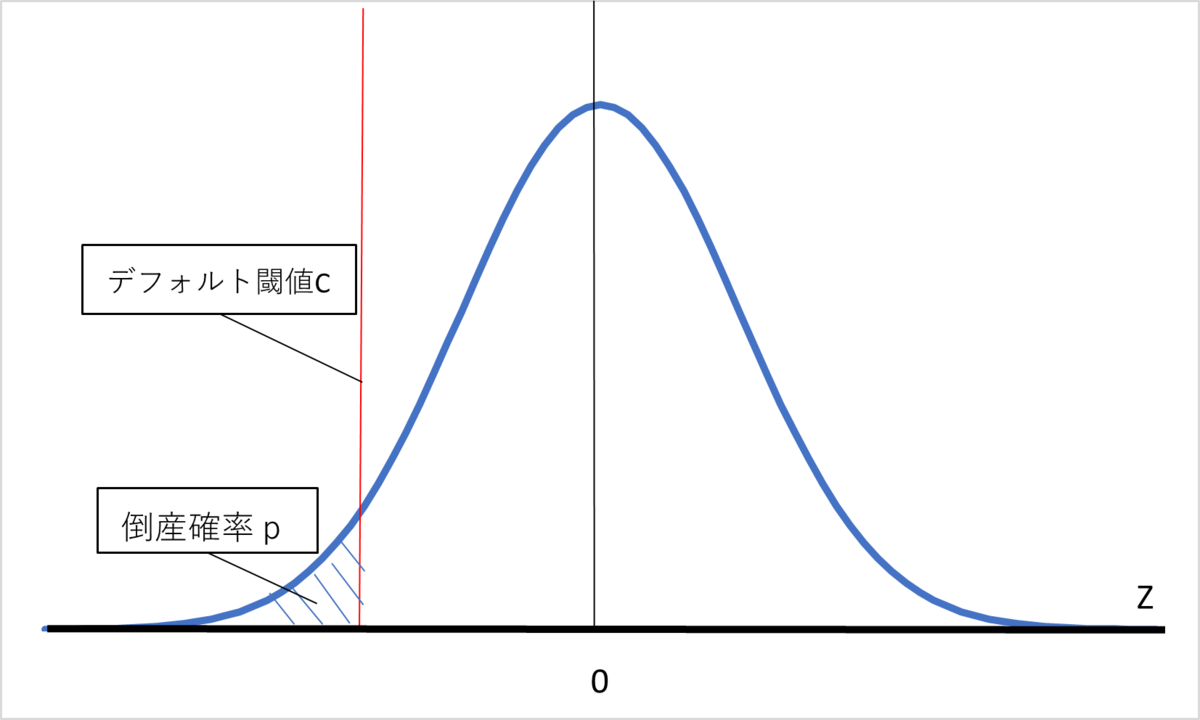
デフォルト閾値は、標準正規分布関数の逆関数で表すことができる。以下の図のように、Ziの標準正規分布にデフォルト閾値Ciを設定すると、青斜線で囲まれた部分の面積はデフォルト確率pに等しくなる。この関係から、デフォルト確率pが分かっていれば、デフォルト閾値Cも求めることができる。
③モンテカルロ・シミュレーションによる損失分布の推計
企業iについて、企業価値Ziとデフォルト閾値Cを比較し、ZiがCを下回った場合、損失Liが発生する。
モンテカルロシミュレーション※により、X,Yについて標準正規乱数(0から1の値を取り標準正規分布に従う乱数)を生成、シミュレートされたZiとCiを比較し、発生した損失額とその頻度(確率)について度数分布表を作成する。こうして、以下に示したような損失分布の推計が可能となる。
※モンテカルロ・シミュレーションとは、乱数を用いて確率的な事象の予想値を算出する手法。

3つのリスク指標
ここで、信用リスクに関する3つの指標について概説する。
①期待損失額(EL)
損失額の平均値。リスクをとって与信を行う以上、この額は所与のものとして背負わなければならない。よって、貸倒引当金等でカバーすることが期待される。
②VaR
VaRとは、一言でいえば「起こり得る最大損失額」ということができる。リーマンショックなど、日常的には起こらないもののいざ起こった時に大きな損失が発生するようなイベントに備え、将来こうした低確率ではあっても発生すれば大きな損失をあらかじめ推定し、それを「リスク」として捉える、というのがVaRの基本的な考え方である。
そして、VaRの定義をより正確に言えば、「(過去のデータをもとに、ある一定の確率の範囲内で、将来のある一定期間のうちに)起こり得る最大損失額(の推計値)」ということができる。一定の信頼区間(通常99%)の範囲内での最大損失を計算する必要がある。
VaRの基本的な考え方については、以下のページを参照されたい。
③非期待損失(UL)
②のVaRは、一定の確率の範囲内での最大損失である。よって、この②から①の期待損失を差し引いた値は、「予期しない損失」ということができる。つまり、UL=VaR -ELで表すことができる。実際は、「予期しない損失」をあらかじめ想定しておく必要があり、ULの分は自己資本でカバーすることが望ましいとされる。
(参考):
日本銀行金融機構局金融高度化センター(2015)「VaRの計測と検証」
日本銀行 金融機構局金融高度化センター(2007)
「信用リスク計量モデルの基礎と応用」